TheStatic Knowledge
RAG System for Codebase Intelligence
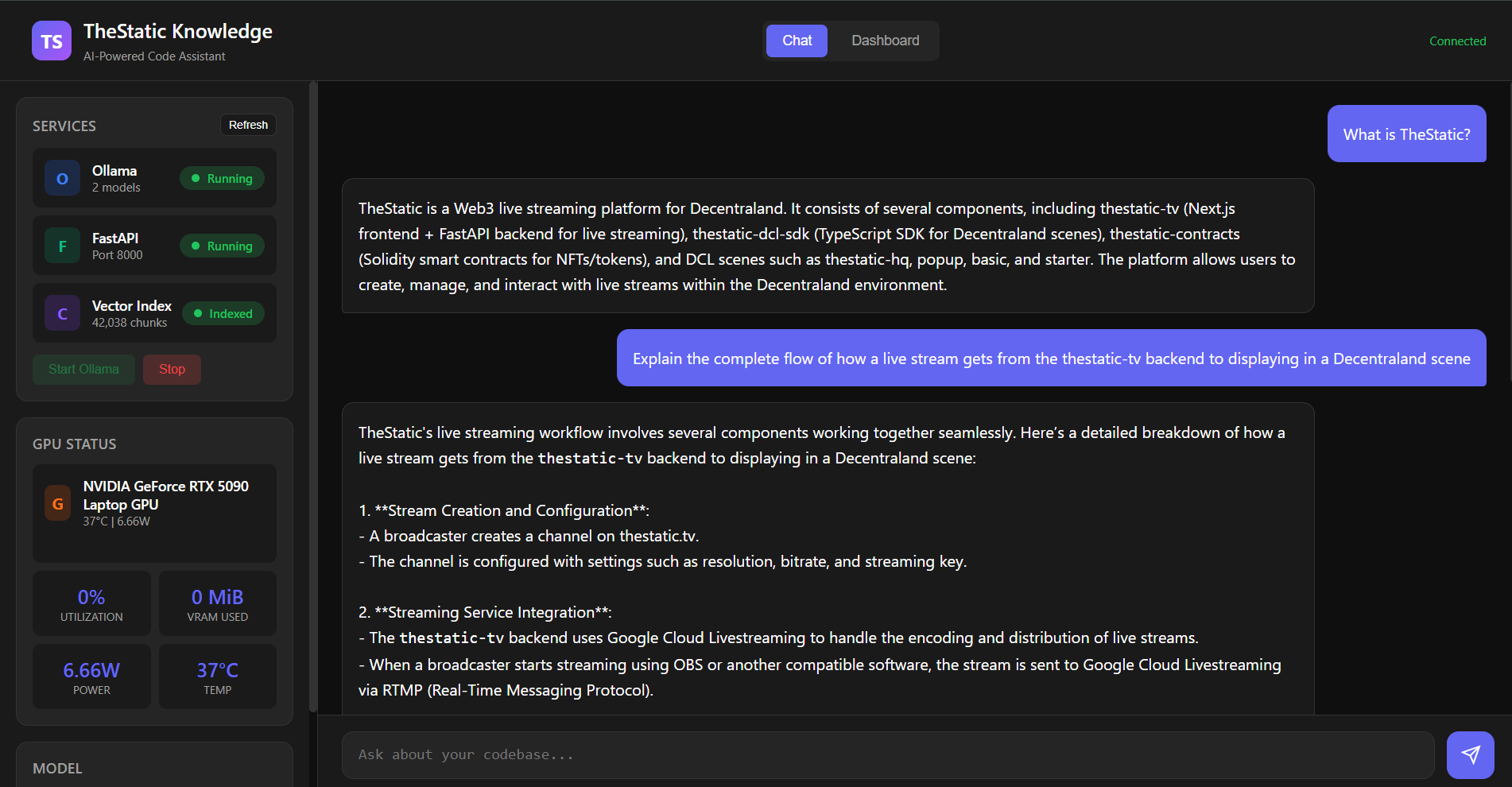
Chat Interface
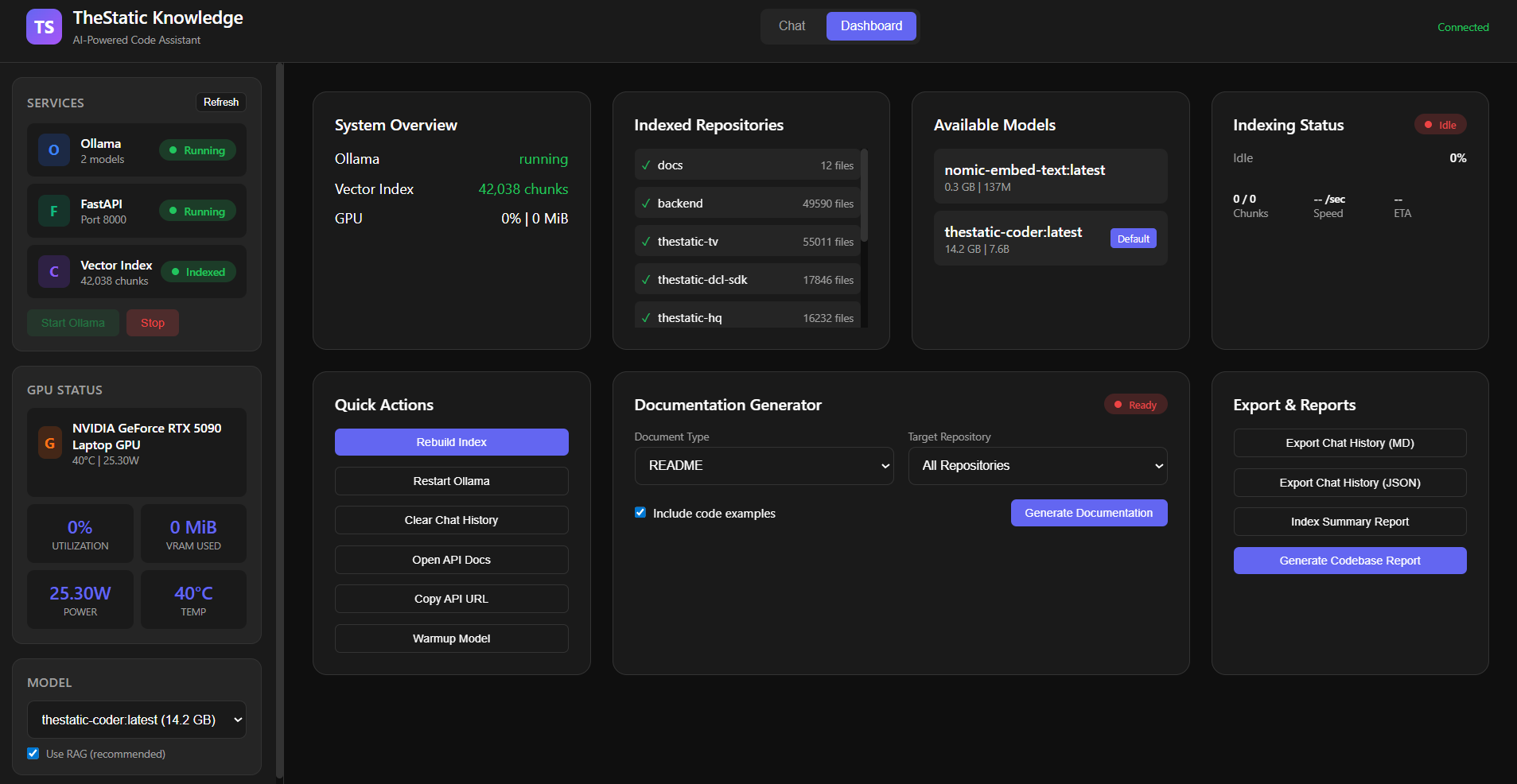
Dashboard
What It Does
TheStatic Knowledge is a production RAG (Retrieval-Augmented Generation) system that indexes the entire TheStatic ecosystem codebase. Ask any question about the architecture, API endpoints, smart contracts, or SDK - get accurate answers with source file references in seconds.
Built for my own development workflow, it eliminates context-switching between repositories and documentation. Query patterns span multiple repos seamlessly, like "How does a stream get from the backend to a Decentraland scene?"
Indexed Repositories
Architecture Highlights
Hybrid Search Pipeline
Two-stage retrieval: vector similarity search (top 10) followed by BM25 keyword scoring and weighted reranking (0.7 vector + 0.3 BM25) to get final 5 results.
GPU-Accelerated Embeddings
Ollama with nomic-embed-text model running on RTX 5090. Batch processing at 500 chunks per request achieves 97 chunks/sec sustained throughput.
Real-Time Index Management
Background indexing with live progress tracking. Indexes entire codebase in ~7 minutes. Persistent ChromaDB storage (356MB) for instant startup.
Clean LLM Output
Optimized prompts prevent instruction echoing. Stop token handling and post-processing ensure professional responses without artifacts.
Technical Details
- Indexes 5 repositories: thestatic-tv, thestatic-dcl-sdk, thestatic-contracts, DCL scenes (hq, popup, basic, starter)
- Recursive character text splitting with code-aware separators (class, function, export)
- Metadata-rich chunks with source path, repo name, file type, and line numbers
- FastAPI backend with async endpoints for chat, indexing, and progress tracking
- Web dashboard with real-time chat interface and indexing progress visualization
- BM25 scoring using term frequency, inverse document frequency, and length normalization
RAG Pipeline
1. LOAD - Read files from 5 repositories (.py, .ts, .sol, .md, .json)
2. SPLIT - Chunk with code-aware separators (500-1000 chars, 100 overlap)
3. EMBED - Generate 768-dim vectors via Ollama (nomic-embed-text)
4. STORE - Persist to ChromaDB with metadata (source, repo, type)
5. QUERY - Embed question, vector search (top 10)
6. RERANK - BM25 keyword scoring, weighted combine, top 5
7. GENERATE - LLM with context, clean response with sources
Example Query
"Explain the complete flow of how a live stream gets from the backend to a Decentraland scene"
The RAG system retrieves context from:
- thestatic-tv/ - GCP Livestream API, RTMP ingest, HLS encoding
- thestatic-dcl-sdk/ - SDK video player component, scene integration
- thestatic-hq/ - How the venue uses the SDK
Response synthesizes the complete pipeline: broadcaster -> RTMP -> GCP -> HLS -> CDN -> SDK -> scene display